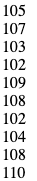SQL RANK, DENSE_RANK, ROW_NUMBER
SQL (Structured Query Language) is a very powerful tool to interact with databases as we all know.
Some more advanced functions, such as window functions in particular, are even more powerful! A window function, as the name may suggest, enables you to compute a row-level assignment based on a defined range or “window”. You can Google it if you’re still lost…
I want to primarily focus on 3 window functions in this write-up that are often [mistakenly] used interchangeably. It is very important to understand what differentiates RANK vs DENSE_RANK vs ROW_NUMBER, and when to use which one.
RANK
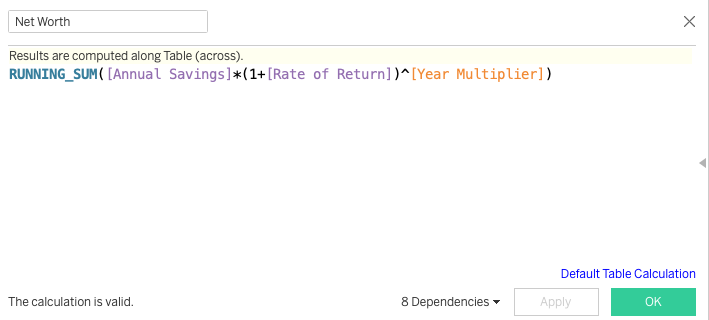
RANK assigns a sequential number to a record based on the partition and order by operators. For example, if we use RANK based on Price, this will rank each row based Price. In doing so, if multiple records share the same Price, they will share the same rank. The immediate next row with a different Price will have a different rank, however it will be incremented by the number of additional rows the prior rank had.
DENSE_RANK
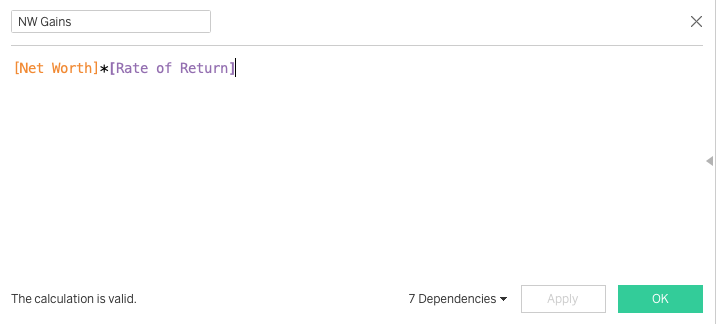
DENSE_RANK works similar to the RANK function, in that it assigns a sequential number to a record based on the partition and order by operators. Where it differs is on the immediate row following a set of records that share the same rank. The DENSE_RANK window function will assign the very next sequential number of the preceding rank, unlike RANK. As a result, there are no gaps when using DENSE_RANK as opposed to RANK.
ROW_NUMBER
ROW_NUMBER brings something different and potentially more useful to the table. This assigns a sequential number (based on price for example) to each record, however no 2 records share the same row number. For example, if 2 or more records share the same price, they will still have a sequential rank (such as 1, 2, 3) instead of (1, 1, 1) if we had used RANK or DENSE_RANK instead.
Let’s suppose we have a dataset consisting of customer_id, item_id and price, and we’ve applied all 3 window functions as:
row_number() over (order by price)
rank() over (order by price)
dense_rank() over (order by price)
Here is the output we’d expect for each.
| Customer_ID | Item_ID | Price | ROW_NUMBER | RANK | DENSE_RANK |
| 1 | 228 | 200 | 1 | 1 | 1 |
| 1 | 255 | 200 | 2 | 1 | 1 |
| 1 | 212 | 200 | 3 | 1 | 1 |
| 2 | 900 | 500 | 4 | 4 | 2 |
Each of these 3 window functions are powerful and useful based on different scenarios. It’s important to understand when and how to use which one for proper results.